Table of Contents
Heterogeneous computing
Modern computing architectures are typically heterogenous: the computing power on a node is divided across multiple asymmetric computing devices. A typical example is a cluster where each node includes one or more CPUs, providing compute with multiple threads that all share memory, and one or more GPUs, which may or may not share memory with each other and the CPUs. NEML2 provides software infrastructure to efficiently divide, send, recover, and merge batched constitutive model updates across multiple asymmetric compute devices.
- Note
- Currently NEML2 only supports CPU and CUDA compute devices. Additional accelerators supported by pytorch including Apple mps and Intel xpu may also work, but are not officially supported.
NEML2 manages work scheduling, dispatch, and joining with two types of objects: dispatchers and schedulers. These objects divide up work along a single batch axis by subdividing that axis into smaller chunks (sub-batches) to run on a given device.
Work dispatchers
NEML2 currently only has a single type of work dispatcher with two general types of behavior. The calling program (for example in NEML2 itself the driver routine) selects which behavior it wants by invoking the dispatcher with either the run_async or run_sync methods. The NEML2 driver routines can use either method, controlled by the async_dispatch option to the driver.
When calling run_async the dispatcher maintains a main thread which schedules and distributes work according the algorithm provided by the selected work scheduler. The main thread dispatches the work to a thread pool that maintains a specific thread for each device. The thread picks up the task (representing a batch of work), sends the work to the device, and returns the work, once completed, to the main thread.
With run_sync the dispatcher schedules work per the scheduler but only runs work sequentially with the single, main NEML2 thread. This model does not provide parallel execution on multiple devices but it's useful for debugging schedulers and functions adequately for schedulers only sending work to a single device.
Setting up the work dispatcher requires providing it with lambda functions describing how to:
- Actually run a sub-batch of work on a device
- Reduce the final collection of sub-batches into a single result
- Preprocess a sub-batch before running it (for example, send it to the device)
- Postprocess a sub-batch before joining (for example, send it back to the cpu)
- Initialize the device thread.
NEML2 provides helper routines for assembling these lambdas for models returning the value of the model and/or the first derivatives of the results with respect to the inputs.
Work schedulers
A work scheduler determines how to divide the full batch of model updates into smaller sub-batches and assign those to different compute devices. NEML2 provides several types of schedulers representing a combination of scheduling models:
- A single CPU task has exclusive access to a single compute device.
- A single CPU task has exclusive access to one or more compute devices.
- Multiple CPU tasks share access to one or more compute devices (this is work in progress and not available in the current release of NEML2).
A CPU task here can either mean a single program calling NEML2, for example the neml2 executable provided with the NEML2 release, or a single MPI rank in a distributed parallel application. The third type of scheduler covers the most general heterogenous compute architecture, where a collection of local CPU threads have shared access to a collection of accelerator devices. However, the first two types of schedulers can also be used in distributed computing environments, with the caveat that each task/MPI rank must have exclusive access to a collection of accelerators.
SimpleScheduler
The SimpleScheduler is the simplest option. It dispatches work from a single instance of NEML2 to a single device. The user provides:
- The torch-compatible name of the target device, e.g. "cuda:0".
- A device sub-batch size, which is the amount of work the scheduler will consider sending to the device at once.
- Optionally, a device capacity. The dispatcher will continue to send sub-batches to the device until it is at capacity, then wait for it to complete some work before sending additional sub-batches. The default capacity is the sub-batch size, meaning the dispatcher will send a single sub-batch and wait for the device to finish before sending another.
The animation below illustrates how the simple scheduler sends work to a device.
This animation shows the dispatcher sending sub-batches to the device until it reaches capacity. The dispatcher then blocks until the device completes a sub-batch, at which it sends another sub-batch to fill the device back to capacity. This pattern of work continues until the scheduler and dispatcher complete the entire, original batch of work.
This scheduling algorithm is useful:
- To determine the optimal sub-batch size for a single device. Typically there is an optimal sub-batch size for a given model. The size will depend on the model, the delay in sending data to the device, and the device throughput. In practice it's best to determine that optimal size empircally by a numerical experiment and then reuse the optimal batch size in the more sophisticated scheduling algorithms.
- In cases where each NEML2 instance, for example each MPI rank, only has exclusive access to a single accelerator. For example, running one MPI rank per node and each node has a single GPU.
It also demonstrates the basic concepts applied in other schedulers.
SimpleMPIScheduler
The SimpleMPIScheduler is an extension of the SimpleScheduler which better distributes work in MPI parallel applications calling NEML2. This scheduler assigns each MPI rank a unique accelerator device out of a list of devices provided by the user. Each MPI rank sends work to its assigned device exclusively, using the same algorithm for work scheduling as in the SimpleScheduler. The difference in inputs between the SimpleMPIScheduler and the SimpleScheduler is just that the user now provides a list of devices, a list of sub-batch sizes, and (optionally), a list of capacities. Each item in the list is a single device available to MPI ranks.
This scheduler assigns a rank to a device by first forming a local MPI communicator over the MPI ranks running on a single compute node (determined by the hostname provided by the MPI_Get_processor_name function). Each MPI rank in the communicator is assigned one device from the list provided by the user. The user must provide at least as many devices as the local communicator has MPI ranks. This approach limits the number of MPI ranks a user can launch per node to the number of available accelerators. For example, if a compute node has one CPU with 16 threads and 8 GPU accelerators the host application can only run 8 MPI ranks per node. The scheduler will report an error if the host application tries to run it with more local ranks than user supplied devices. This often means the user will need to pin ranks to ensure their MPI application assigns only the required number of ranks per node.
This scheduler is useful for larger parallel jobs, but may limit the overall performance of the application as often there are more CPU cores available for MPI ranks than accelerators on a node.
StaticHybridScheduler
The StaticHybridScheduler allows a single instance of NEML2 to distribute work to many compute devices at once. The user provides a list of devices, sub-batch sizes, capacities, and (optionally) priorities. The scheduler will greedily assign work to fill up each device, using the priority if provided to determine in which order to dole out work. The work dispatcher will then run this work in parallel on all devices via the thread pool discussed above.
This scheduler currently provides the best throughput for cases where a single NEML2 instance has access to multiple devices. The device list can include the CPU itself so that the CPU thread running NEML2 can do work at the same time the accelerators are working on their sub-batches. We suggest the user determine the optimal sub-batch size for each device, for example using the SimpleScheduler, prior to running large jobs with this scheduling algorithm.
The animation below illustrates how the static hybrid scheduler sends work to multiple devices.
The downside to this scheduler is that it does not handle MPI parallelism. Distributed parallel programs invoking NEML2 can only use this scheduler if each MPI rank has exclusive access to all accelerators on a compute node, i.e. running one MPI rank per physical node.
Event tracing
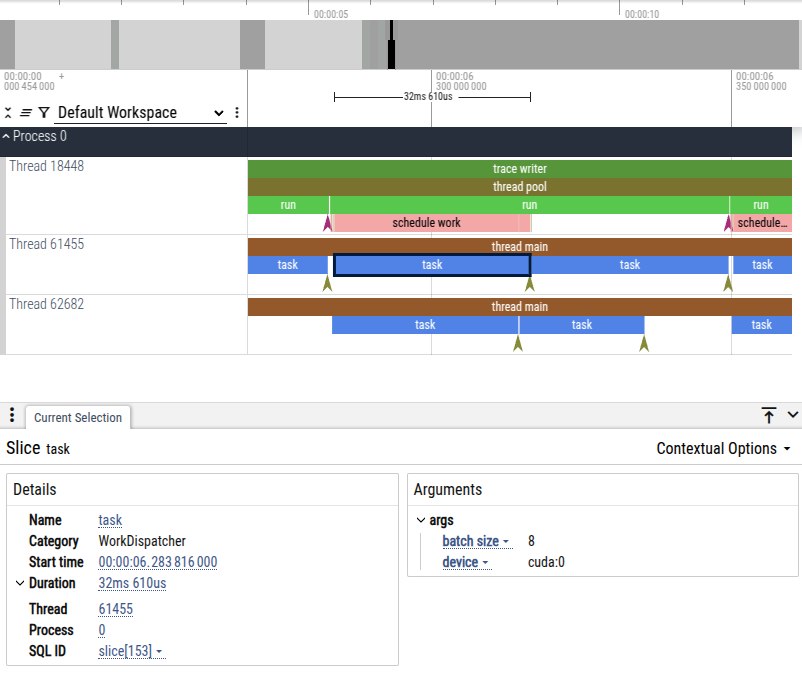
Work scheduling and dispatching can get complicated quickly as more sophisticated scheduling strategies are used, and asynchronous dispatching further builds upon such complexity. Benchmarking and profiling can give us a rough idea on whether the scheduler and dispatcher are coordinating as expected, by examining the wall time against theoretical bounds. However, such approach is less ideal especially in hybrid computing environments.
In addition to benchmarking and profiling, NEML2 offers the capability of logging events related to scheduling and dispatching. The events are logged into a trace file in the Chrome trace format. The trace file is essentially a JSON array of events.
To enable event tracing, inside the input file, set Schedulers/*/trace_file to the path of the output trace file, i.e. path/to/trace.json. While the work dispatcher and scheduler are coordinating the tasks, key events are continuously written to the trace file. After all calculations are complete, the trace file can be visualized using many third-party tools:
- Chrome trace viewer, the canonical Chrome trace file viewer.
- Perfetto, the successor of Chrome trace viewer.
- Speedscope with unique features such as "left heavy" and "sandwich" modes.
Below is an example screenshot from the Chrome trace viewer: