This is a modification of the deterministic example to use Stochastic Variational Inference (SVI) to train a hierarchical statistical model rather than a simple deterministic model. The modifications required to train a model with SVI only start half way through the example — the rest is the same as the previous, deterministic example.
This is a complete example of using the pyzag bindings to NEML2 to calibrated a material model against experimental data. demo_model.i defines the constitutive model, which is a structural material model describing the evolution of strain and stress in the material under mechanical load. The particular demonstration is a fairly complex model where the material responds differently as a function of both temperature and strain rate. The model also reduces the full 3D form of the constitutive model to 1D, where the final model is driven by an axial strain and all the other stress components are zero.
In this example we:
- Load the model in from file and wrap it for use in pyzag
- Setup a grid of "experimental" conditions spanning several strain rates and temperatures
- Replace the original model parameters with samples from a normal distrubtion, centered on the orignial model mean, and run the model over the experimental conditions. This then becomes our synthetic input data.
- Replace the original model parameters with random priors from wide normal distributions (with means sampled from the original distributions).
- Setup the model for training with gradient-descent methods by scaling the model parameters and resulting gradient values.
- Use SVI to train the model against the synthetic data.
- Plot the results and print the trained parameter values, to see how close we can come to the true values.
Because it's difficult to consider random variation across a wide range of test conditions, we also consider a set of repeated experiments at the same test condition. Simulating the same test many times gives a clear idea of the amount of variability in the synthetic data and for the corresponding trained model.
import torch
import torch.distributions as dist
import neml2
from pyzag import nonlinear, reparametrization, chunktime, stochastic
import matplotlib.pyplot as plt
import tqdm
import pyro
from pyro.infer import SVI, Trace_ELBO, Predictive
Setup parameters related to how we train the model
Choose which device to use. The nchunk parameter controls the time integration in pyzag. pyzag can vectorize the time integration itself, providing a larger bandwidth to the compute device. This helps speed up the calculation, particularly when running on a GPU. The optimal value will depend on your compute device.
torch.manual_seed(42)
torch.set_default_dtype(torch.double)
if torch.cuda.is_available():
dev = "cuda:0"
else:
dev = "cpu"
device = torch.device(dev)
nchunk = 100
Setup the synthetic experimental conditions
Setup the loading conditions for the "experiments" we're going to run. These will span several strain rates (nrate) and temperatures (ntemperature). Overall, we'll run nbatch experiments. Also setup the maximum strain to pull the material through max_strain and the number of time steps we're going to use for integration ntime.
nrate = 5
ntemperature = 10
nbatch = nrate * ntemperature
max_strain = 0.25
ntime = 100
rates = torch.logspace(-6, 0, nrate, device=device)
temperatures = torch.linspace(310.0, 1190.0, ntemperature, device=device)
Conditions for the repeated experiment
Also choose a single condition to repeat multiple times to give a clearer idea of the variability captured in the synthetic data and model.
nrepeat = 100
single_temperature = 600.0
single_rate = 1.0e-3
Define the variability in the synthetic data and for our initial guess at the parameters
These control the variability in the synthetic data (actual_cov) and the variability of the initial guess at the parameter values (guess_cov). Also provide the actual values and a prior on the white noise included on top of the experimental measurements.
actual_cov = 0.02
actual_noise_scale = 5.0
prior_cov = 0.05
prior_noise_scale = 10.0
guess_cov = 0.1
Setup the actual model
This class is a thin wrapper around the underlying pyzag wrapper for NEML2. All it does is take the input conditions (time, temperature, and strain), combine them into a single tensor, call the pyzag wrapper, and return the stress.
class SolveStrain(torch.nn.Module):
"""Just integrate the model through some strain history
Args:
discrete_equations: the pyzag wrapped model
nchunk (int): number of vectorized time steps
rtol (float): relative tolerance to use for Newton's method during time integration
atol (float): absolute tolerance to use for Newton's method during time integration
"""
def __init__(self, discrete_equations, nchunk=1, rtol=1.0e-6, atol=1.0e-4):
super().__init__()
self.discrete_equations = discrete_equations
self.nchunk = nchunk
self.cached_solution = None
self.rtol = rtol
self.atol = atol
def forward(self, time, temperature, loading, cache=False):
"""Integrate through some time/temperature/strain history and return stress
Args:
time (torch.tensor): batched times
temperature (torch.tensor): batched temperatures
loading (torch.tensor): loading conditions, which are the input strain in the first base index and then the stress (zero) in the remainder
Keyword Args:
cache (bool): if true, cache the solution and use it as a predictor for the next call.
This heuristic can speed things up during inference where the model is called repeatedly with similar parameter values.
"""
if cache and self.cached_solution is not None:
solver = nonlinear.RecursiveNonlinearEquationSolver(
self.discrete_equations,
step_generator=nonlinear.StepGenerator(self.nchunk),
predictor=nonlinear.FullTrajectoryPredictor(self.cached_solution),
nonlinear_solver=chunktime.ChunkNewtonRaphson(rtol=self.rtol, atol=self.atol),
)
else:
solver = nonlinear.RecursiveNonlinearEquationSolver(
self.discrete_equations,
step_generator=nonlinear.StepGenerator(self.nchunk),
predictor=nonlinear.PreviousStepsPredictor(),
nonlinear_solver=chunktime.ChunkNewtonRaphson(rtol=self.rtol, atol=self.atol),
)
control = torch.zeros_like(loading)
control[..., 1:] = 1.0
forces = {
}
forces = [forces[key] for key in self.discrete_equations.fvars]
forces = (
.assemble()
.tensors[0]
)
state0 = torch.zeros(
forces.shape[1:-1] + (self.discrete_equations.nstate,), device=forces.device
)
result = nonlinear.solve_adjoint(solver, state0, len(forces), forces)
if cache:
self.cached_solution = result.detach().clone()
return result[..., 0:1]
The symmetric second order tensor.
Definition SR2.h:46
Scalar.
Definition Scalar.h:38
Definition TransientDriver.h:32
Sparse representation of a vector consisting of a list of tensors and their layout.
Definition SparseVector.h:36
Actually setup the model
Load the NEML model from disk, wrap it in both the pyzag wrapper and our thin wrapper class above. Exclude some of the model parameters we don't want to train.
nmodel = neml2.load_nonlinear_system("demo_model.i", "eq_sys")
nmodel.to(device=device)
pmodel = neml2.pyzag.NEML2PyzagModel(
nmodel,
exclude_parameters=[
"elasticity_E",
"elasticity_nu",
"R_X",
"d_X",
"mu_X",
"mu_Y",
"yield_zero_sy",
],
)
model = SolveStrain(pmodel)
Create the input tendors
Actually setup the full input tensors based on the parameters above
time = torch.zeros((ntime, nrate, ntemperature), device=device)
loading = torch.zeros((ntime, nrate, ntemperature, 6), device=device)
temperature = torch.zeros((ntime, nrate, ntemperature), device=device)
for i, rate in enumerate(rates):
time[:, i] = torch.linspace(0, max_strain / rate, ntime, device=device)[:, None]
loading[..., 0] = torch.linspace(0, max_strain, ntime, device=device)[:, None, None]
for i, T in enumerate(temperatures):
temperature[:, :, i] = T
time = time.reshape((ntime, -1, 1))
temperature = temperature.reshape((ntime, -1, 1))
loading = loading.reshape((ntime, -1, 6))
single_times = (
torch.linspace(0, max_strain / single_rate, ntime, device=device)
.unsqueeze(-1)
.expand((ntime, nrepeat))
.unsqueeze(-1)
)
single_temperatures = torch.full_like(single_times, single_temperature)
single_loading = torch.zeros((ntime, nrepeat, 6), device=device)
single_loading[..., 0] = torch.linspace(0, max_strain, ntime, device=device).unsqueeze(-1)
Replace the model parameters with random values
Sampled from a normal distribution controlled by the actual_cov parameter.
This controls the randomness in the input synthetic test data
actual_parameter_values = {}
for n, p in model.named_parameters():
actual_parameter_values[n] = p.data.detach().clone().cpu()
ndist = dist.Normal(p.data, torch.abs(p.data) * actual_cov).expand((nbatch,) + p.shape)
p.data = ndist.sample().to(device)
Run the model to generate the synthetic data
with torch.no_grad():
data = model(time, temperature, loading)
data = torch.normal(data, actual_noise_scale)
Plot the synthetic data
plt.figure()
plt.plot(loading.cpu()[..., 0], data[..., 0].cpu())
plt.xlabel("Strain (mm/mm)")
plt.ylabel("Stress (MPa)")
plt.title("Input data -- all conditions")
plt.show()
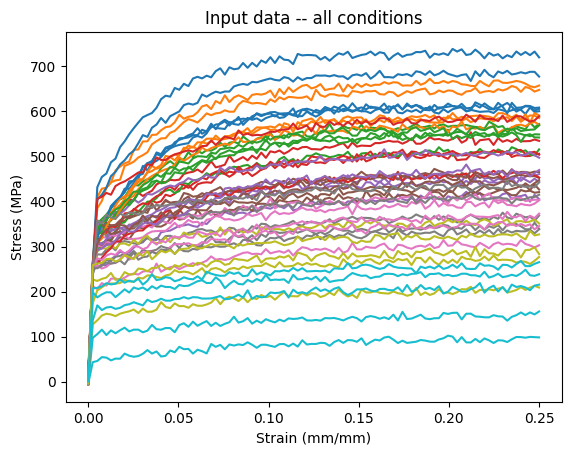
png
Now sample at run at a fixed condition
The idea being to clearly see the variability in repeated trials at a fix condition.
for n, p in model.named_parameters():
ndist = dist.Normal(
actual_parameter_values[n], torch.abs(actual_parameter_values[n]) * actual_cov
).expand((nrepeat,) + actual_parameter_values[n].shape)
p.data = ndist.sample().to(device)
with torch.no_grad():
single_data = model(single_times, single_temperatures, single_loading)
single_data = torch.normal(single_data, actual_noise_scale)
plt.figure()
plt.plot(single_loading.cpu()[..., 0], single_data[..., 0].cpu())
plt.xlabel("Strain (mm/mm)")
plt.ylabel("Stress (MPa)")
plt.title("Input data -- single condition")
plt.show()
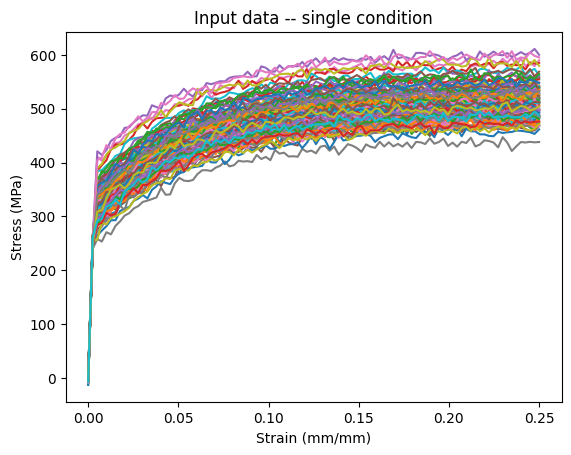
png
Setup the model for training
Replace the parameter values with random initial guesses, with variability controlled by the guess_cov parameter.
guess_parameter_values = {}
for n, p in model.named_parameters():
p.data = torch.normal(
actual_parameter_values[n], torch.abs(actual_parameter_values[n]) * guess_cov
).to(device)
guess_parameter_values[n] = p.data.detach().clone()
model.discrete_equations._update_parameter_values()
Scale the model parameters
Our material model parameters have units. In general, the parameter values will have different magnitudes from each other, which affects the scale of the gradients. Unbalanced gradients in turn affect the convergence of gradient descent optimization methods.
Typically we'd scale the training data to fix this problem. However, again our data has units and a physical meaning we want to preserve.
As an alternative we can scale the parameter values themselves both to clip the values to a physical range and to scale the gradients and hopefully improve the convergence of the optimization step. We do that here, in a way that should be mostly invisible to the training algorithms.
A_scaler = reparametrization.RangeRescale(
torch.tensor(-12.0, device=device), torch.tensor(-4.0, device=device)
)
B_scaler = reparametrization.RangeRescale(
torch.tensor(-1.0, device=device), torch.tensor(-0.5, device=device)
)
C_scaler = reparametrization.RangeRescale(
torch.tensor(-8.0, device=device), torch.tensor(-3.0, device=device)
)
R_scaler = reparametrization.RangeRescale(
torch.tensor([0.0, 0.0, 0.0, 0.0], device=device),
torch.tensor([500.0, 500.0, 500.0, 500.0], device=device),
)
d_scaler = reparametrization.RangeRescale(
torch.tensor([0.01, 0.01, 0.01, 0.01], device=device),
torch.tensor([50.0, 50.0, 50.0, 50.0], device=device),
)
model_reparameterizer = reparametrization.Reparameterizer(
{
"discrete_equations.A_value": A_scaler,
"discrete_equations.B_value": B_scaler,
"discrete_equations.C_value": C_scaler,
"discrete_equations.R_Y": R_scaler,
"discrete_equations.d_Y": d_scaler,
},
error_not_provided=True,
)
model_reparameterizer(model)
Convert the model to a hierarchical statistical model
We now convert the model from deterministic to a hierarchnical statistical model. We use the pyzag mapper functionality to convert the model with two levels. The top level statistics are common to the entire data set, i.e. all tests in the synthetic data, while the lower-level distributions provide statistics for each individual sample of material. Each parameter is converted to a prior with the initial mean value selected based on the (random) deterministic values assigned above. We also provide a prior on the level of white noise included in the experimental measurements.
mapper = stochastic.MapNormal(prior_cov)
hsmodel = stochastic.HierarchicalStatisticalModel(
model, mapper, torch.tensor(prior_noise_scale, device=device)
)
Sample the prior model to compare to the repeated test
This is just for visualization, to see how far away our prior model starts from the true distribution
nreps = 5
predict = Predictive(hsmodel, num_samples=nreps)
with torch.no_grad():
untrained_single = predict(
single_times[:, :nbatch], single_temperatures[:, :nbatch], single_loading[:, :nbatch]
)["obs"]
flat_untrained = untrained_single.transpose(0, 1).reshape(ntime, nreps * nbatch, 1)
plt.figure()
plt.plot(
single_loading[:, 0, 0].cpu(),
torch.mean(flat_untrained, dim=1)[:, 0].cpu(),
ls="-",
color="k",
lw=4,
label="Prior mean",
)
p = 0.05
n_lb = int(p * nreps * nbatch)
n_ub = int((1 - p) * nreps * nbatch)
plt.fill_between(
single_loading[:, 0, 0].cpu(),
torch.kthvalue(flat_untrained, n_lb, dim=1)[0][:, 0].cpu(),
torch.kthvalue(flat_untrained, n_ub, dim=1)[0][:, 0].cpu(),
color="tab:blue",
alpha=0.8,
label="90% prediction",
)
plt.plot(
single_loading.cpu()[..., 0],
single_data[..., 0].cpu(),
color="k",
lw=0.3,
label="Data",
)
handles, labels = plt.gca().get_legend_handles_labels()
plt.xlabel("Strain")
plt.ylabel("Stress")
plt.legend(handles[:3], labels[:3], loc="best")
plt.show()
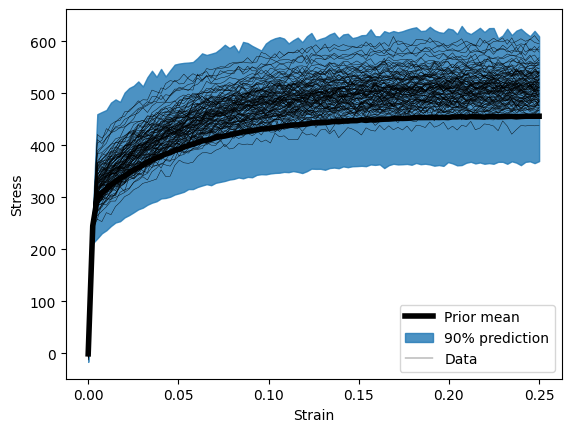
png
Setup a guide and training hyperparameters
Use AutoDelta to get a MAP estimate of the parameters.
Setup the SVI problem and the usual sorts of training hyperparameters
guide = pyro.infer.autoguide.guides.AutoDelta(hsmodel)
lr = 1.0e-3
niter = 150
num_samples = 1
optimizer = pyro.optim.ClippedAdam({"lr": lr})
loss = Trace_ELBO(num_particles=num_samples)
svi = SVI(hsmodel, guide, optimizer, loss=loss)
Run the training loop
titer = tqdm.tqdm(
range(niter),
bar_format="{desc}{percentage:3.0f}%|{bar}|{n_fmt}/{total_fmt}{postfix}",
)
titer.set_description("Loss:")
loss_history = []
for i in titer:
closs = svi.step(time, temperature, loading, results=data)
loss_history.append(closs)
titer.set_description("Loss: %3.2e" % closs)
plt.figure()
plt.plot(loss_history, label="Training")
plt.xlabel("Iteration")
plt.ylabel("ELBO")
plt.legend(loc="best")
plt.title("Training loss")
plt.show()
Loss: 1.52e+04: 100%|██████████|150/150
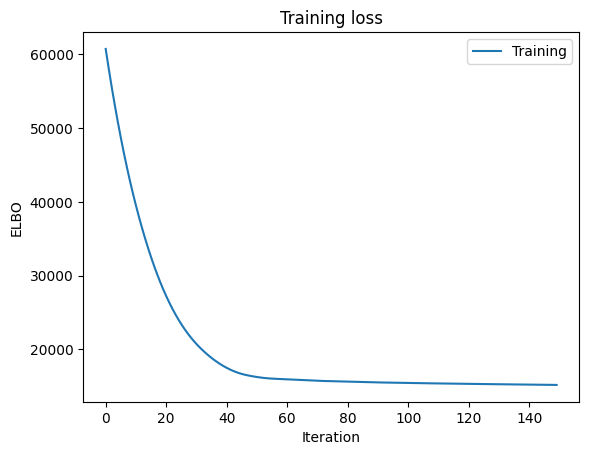
png
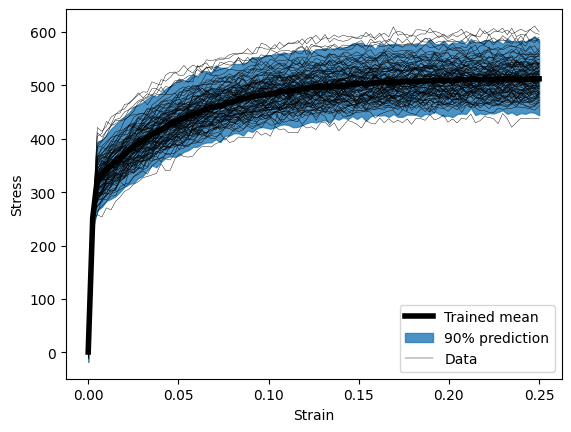
Go back and sample our repeated case
nreps = 5
predict = Predictive(hsmodel, guide=guide, num_samples=nreps)
with torch.no_grad():
trained_single = predict(
single_times[:, :nbatch], single_temperatures[:, :nbatch], single_loading[:, :nbatch]
)["obs"]
flat_trained = trained_single.transpose(0, 1).reshape(ntime, nreps * nbatch, 1)
plt.figure()
plt.plot(
single_loading[:, 0, 0].cpu(),
torch.mean(flat_trained, dim=1)[:, 0].cpu(),
ls="-",
color="k",
lw=4,
label="Trained mean",
)
p = 0.05
n_lb = int(p * nreps * nbatch)
n_ub = int((1 - p) * nreps * nbatch)
plt.fill_between(
single_loading[:, 0, 0].cpu(),
torch.kthvalue(flat_trained, n_lb, dim=1)[0][:, 0].cpu(),
torch.kthvalue(flat_trained, n_ub, dim=1)[0][:, 0].cpu(),
color="tab:blue",
alpha=0.8,
label="90% prediction",
)
plt.plot(single_loading.cpu()[..., 0], single_data[..., 0].cpu(), color="k", lw=0.3, label="Data")
handles, labels = plt.gca().get_legend_handles_labels()
plt.xlabel("Strain")
plt.ylabel("Stress")
plt.legend(handles[:3], labels[:3], loc="best")
plt.show()
png
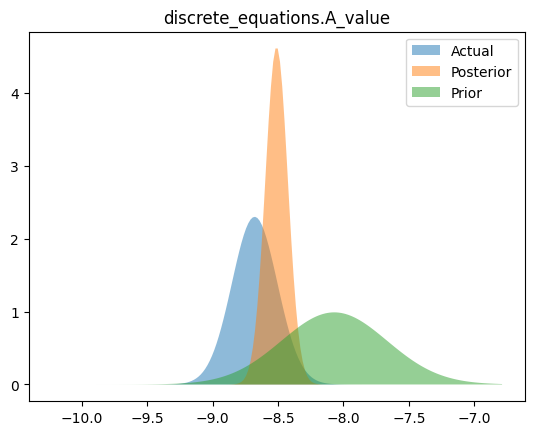
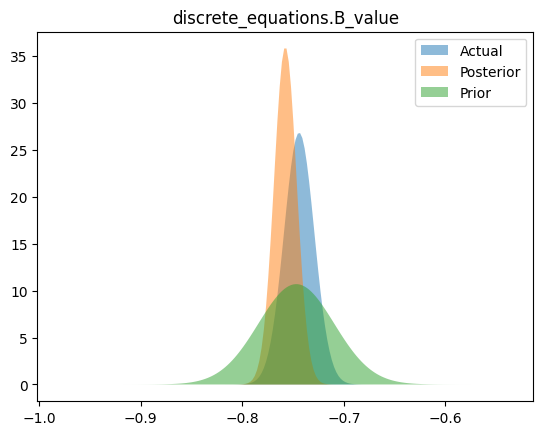
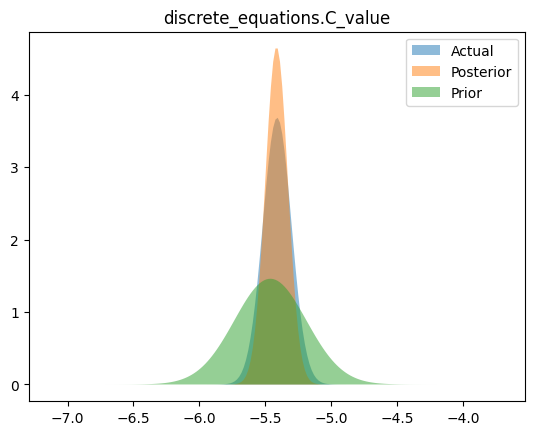
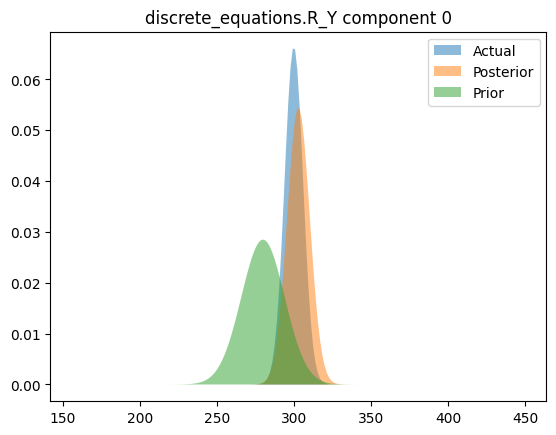
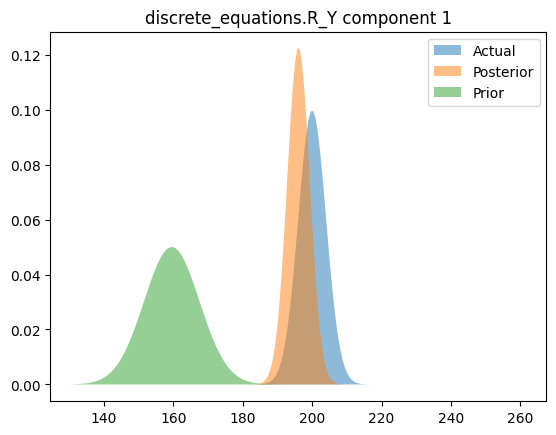
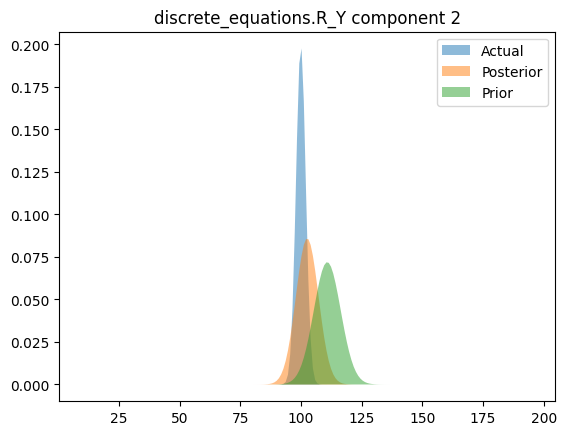
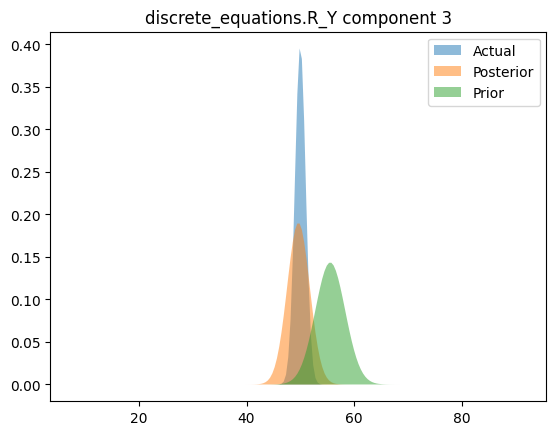
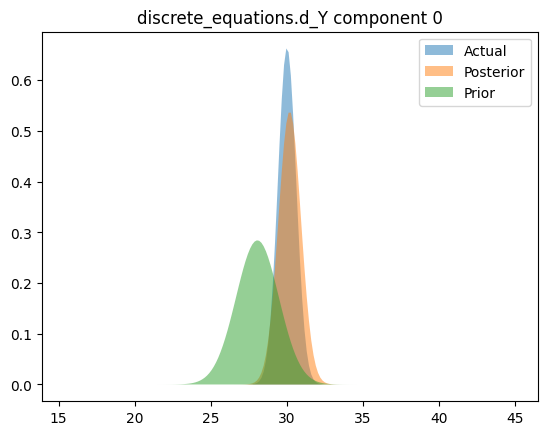
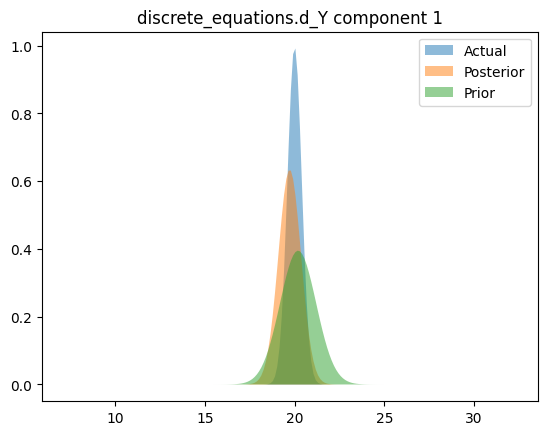
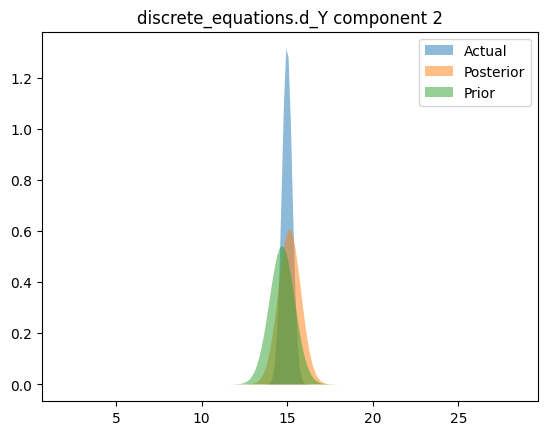
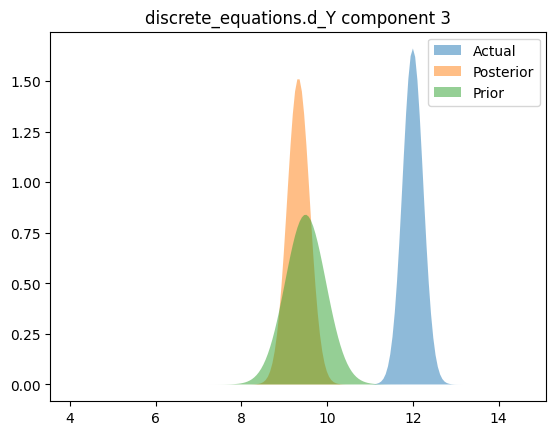
Compare priors, true posteriors, and inferred posteriors
for _, _, n in hsmodel.bot:
simple_name = ".".join([n.split(".")[i] for i in [0, 2]])
scaler = model_reparameterizer.map_dict[simple_name]
prior_loc = guess_parameter_values[simple_name]
prior_scale = prior_cov * torch.abs(prior_loc)
actual_loc = actual_parameter_values[simple_name]
actual_scale = actual_cov * torch.abs(actual_loc)
posterior_loc = scaler.forward(pyro.param("AutoDelta." + n + "_loc").detach())
posterior_scale = scaler.forward_std_dev(pyro.param("AutoDelta." + n + "_scale").detach())
if posterior_loc.dim() == 0:
x_range = torch.linspace(
posterior_loc - 20 * posterior_scale,
posterior_loc + 20 * posterior_scale,
200,
device=device,
)
y_posterior = dist.Normal(posterior_loc.cpu(), posterior_scale).log_prob(x_range).exp()
y_actual = dist.Normal(actual_loc, actual_scale).log_prob(x_range).exp()
y_prior = dist.Normal(prior_loc, prior_scale).log_prob(x_range).exp()
plt.figure()
plt.fill_between(x_range.cpu(), y_actual.cpu(), label="Actual", alpha=0.5)
plt.fill_between(x_range.cpu(), y_posterior.cpu(), label="Posterior", alpha=0.5)
plt.fill_between(x_range.cpu(), y_prior.cpu(), label="Prior", alpha=0.5)
plt.legend(loc="best")
plt.title(simple_name)
else:
for i in range(posterior_loc.shape[0]):
x_range = torch.linspace(
posterior_loc[i] - 20 * posterior_scale[i],
posterior_loc[i] + 20 * posterior_scale[i],
200,
device=device,
)
y_posterior = dist.Normal(posterior_loc[i], posterior_scale[i]).log_prob(x_range).exp()
y_actual = dist.Normal(actual_loc[i], actual_scale[i]).log_prob(x_range).exp()
y_prior = dist.Normal(prior_loc[i], prior_scale[i]).log_prob(x_range).exp()
plt.figure()
plt.fill_between(x_range.cpu(), y_actual.cpu(), label="Actual", alpha=0.5)
plt.fill_between(x_range.cpu(), y_posterior.cpu(), label="Posterior", alpha=0.5)
plt.fill_between(x_range.cpu(), y_prior.cpu(), label="Prior", alpha=0.5)
plt.legend(loc="best")
plt.title(simple_name + " component %i" % i)
png
png
png
png
png
png
png
png
png
png
png